
Introduction
An important algorism of artificial intelligence that have appeared in the modern world as essential to solve extremely difficult problems of classification are neural networks. But as the models become larger and complex, they need good amount of computational power and they are prone to overlearn. Neural pruning that refers to the process of removing neurons or the connections between neurons, is now recognized as one of the most successful approaches for the enhancement of the used neural networks [1]. Model pruning carried out using an understanding of the layer characteristics in a neural network model has been demonstrated to greatly improve accuracy and make a notable reduction in resource utilization. In this article we explain what layer-aware models are and examine how neural pruning affects the efficiency of neural networks. At the end of this discussion, you will be in a position to appreciate theoretical framework, practical use, and potential of these advanced methods [2].
(https://www.datature.io/blog/a-comprehensive-guide-to-neural-network-model-pruning)
Understanding Neural Pruning
Neural pruning is a technique of eliminating neurons, synapses or entire layers of a neural network which does not have much negative impact on the performance of network. Given that, the aim of prune is to decrease model complexity in the network to enhance the efficiency of calculation and avoiding overfitting [3].
Pruning can be classified into several types:
- Structured Pruning: This unsubscribes entire filters, neurons and channel from the network.
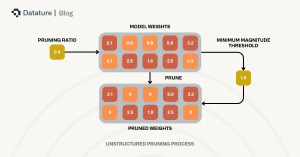
- Unstructured Pruning: Reduces weights of individual neurons and makes the network elements sparse to a certain degree.
- Dynamic Pruning: Changes the topology of the network during training depending on its training parameters’ results.
- Static Pruning: Also employed during the final stages of training and excludes repeatability.
While neural pruning has many applications, one issue to consider when doing pruning is what parts of the network should be pruned. This is where layer aware models come into play.
What Is Layer-Aware Models?
Layer-aware are the neural network model that takes into consideration the distinct function and significance of each layer while pruning. The prior methods of pruning usually employ the same knife treatment to all layers and that is not efficient at all. On the other hand, layer-aware approaches understand that some layers are more sensitive to weights pruning in terms of the overall accuracy required to maintain by the internet network and, therefore, must be pruned more carefully [4].
Key Features of Layer-Aware Models:
Differentiated Pruning Criteria
In this exertion, various layers of a neural network have been assigned to different functions in the decision-making process of the model. The first layer often categorizes simple patterns such as the edge and the texture of the input, the deeper layers capture higher-level features. As a result, if applied haphazardly, pruning these layers common results in a massive loss of performance. Another approach of pruning is called differentiated pruning using different cutting off levels to the various layers based on their significance [5]. For instance, early layers can be assigned small pruning rates to minimize the pruning of features while later layers can allow high pruning rates with little or no impact on the performance of the model. Such differentiation helps to preserve most essential information flows while achieving the overall network optimization.
When using differentiated pruning criteria, one needs to consider function of each layer of the neural network. Sensitivity analysis and contribution scoring can be employed to accurately gauge how critical each layer is within the total output. Since pruning can be done in such different layers, models can get a better accuracy in the same number of parameters.
- Adaptive Pruning Strategies
The dynamic pruning approach changes the way of pruning when training the given network. In contrast to classical structure pruning schemes that fix the pruning ratio for the entire training process, adaptive mechanisms permanently observe the efficacy of each layer in the total accuracy and, contingent on these observations, change pruned values. This dynamic adjustment ensures high performance and robustness to the network even under the architecture complexity.
The shifting importance of layers is a functionality well-grasped by adaptive pruning techniques. For example, early stages of training may involve more weights change in some of the layers compared to deeper layers and vice versa. Moreover, growing models are more efficient and accurate when the pruning criteria are adjusted in real time [6].
Reinforcement learning is a common form of adaptive pruning where the pruning agent, interacts with the model to learn the best pruning strategies given the performance impressions acquired. It makes pruning decision more wisely than the simple global threshold method, which reduces the computational cost while sacrificing the accuracy.
- Layer Importance Metrics
Determining which layers to prune requires reliable metrics that quantify the importance of each layer to the network’s overall performance. Commonly used metrics include:
- Sensitivity Analysis: This involves measuring how small changes in a layer’s parameters affect the network’s accuracy. Layers that have a minimal impact on accuracy can be pruned more aggressively.
- Contribution Scores: Contribution scores assess the significance of a layer’s output in the final prediction. Layers with higher contribution scores are considered more important and are pruned less aggressively.
- Activation Sparsity: Layers with a high degree of sparsity in their activations (i.e., many neurons remaining inactive) can be pruned without significantly impacting performance.
These metrics assist to determine the excess of layers and connections that have a relatively small impact on the results of multinetwork. With such pruning targets, layer-aware models can leave less important areas pruned while maintaining optimum network architecture and performance.
The importance of each layer is usually determined through such means as backpropagation alongside with gradient analysis [7]. These methods usable in giving glimpses on how each layers affect the network’s current output and used as guide on the pruning hours.
How Layer-Aware Models Enhance Classification Accuracy
Layer-aware pruning strategies can significantly improve classification accuracy by preserving the essential features of the network while eliminating redundancies. Below are some ways in which these models achieve this:
Retaining Crucial Features
It is important to note that not all layers will help a network decide. For example, the first layers in a of a Convolutional Neural Network (CNN) mostly identify low levels features like edges or the texture and patterns while deeper layers notice higher levels features. Layer-aware models enable the identification of thinning process layers of a network to keep it capable of making accurate classifications successfully.
Reducing Overfitting
Due to the removal of neurons and connections, layer-aware pruning successfully minimizes the overfitting of the over-cooked model. It simply means that when the ML model tries to adapt fully to the training data by identifying features that may not be useful for the actual prediction the difficulties surface when the model is set to make predictions on new data. Excessive features and data connections inevitably have weaker weight values Training the model with pruned networks and eliminating the connected less important parts helps to generalize the model.
Maximizing Efficiency in Computation
Layer-aware pruning applied to a network reduces the number of parameters with the positive consequence of faster inference times and reduced memory usage. This is even more so when deploying the models on devices with limited resources such as smartphones and Internet of Things devices.
Techniques for Implementing Layer-Aware Pruning
Several techniques have been developed to implement layer-aware pruning effectively. Below are some of the most used methods:
Sensitivity Analysis
More specifically sensitivity analysis means analyzing impact of change in one or another parameter of layer on the general performance of the network. It quantifies its capacity for change in response to alterations of any of the layers and their elements, including neurons or connections. Proposed from the second set of layers which become less affected when they are altered during training are selected as candidates to be pruned more aggressively. Sensitivity analysis can be performed based on a small change in a layer umperterization of the model and examination of the effects on the final output. This layer ensures that only some layers that one cannot afford to corrupt are pruned, hence retaining the best performance of the network [8]
Contribution Scores
Contribution scores indicate an importance of the output of each layer to the final score of the prediction. This metric gives the quantitative measure of contribution of each layer to the decision making of the network. Contribution scores less than layers Li mean that such layers are less important and may hence be removed to make the model slimmer. Usual contribution scores can be calculated by either examining the gradients of the loss about the layer outputs or by comparing the weights of the layers. It is important in helping one eliminate layer that contributes little judgement to the results hence improve of the model.
Regularization-Based Pruning
It can be mentioned that there are other types of regularization like L1 and L2 that work to make the network sparse. These methods enforce penalties on large weights and encourages the pruning out of least relevant connections. Regularization-based pruning incorporates these factors during the training stage and as a result, it easier to landmark and delete useless neurons or connections. L1 regularization results to more sparse networks as it sets those weights equal to zero while L2 regulation brings down the weights in the network but not to zero [6]. They are useful to apply in combination with other pruning approaches to accomplish network slimming.
Reinforcement Learning
Pruning call can also be made more optimal with the help of reinforcement learning because it makes the choice of which Layer’s nodes to prune next a sequence decision. In this approach the model decides on the pruning of operations that would increase accuracy and reduce computational time. The pruning agent feedback is in terms of performance from the model and as a result, it fine tunes the pruning technique it uses. Recurrent pruning plays the key role in the process as it allows changing pruning thresholds during training and, thus, keeps the network efficient and accurate during its work. This technique is particularly fascinating in dense networks where pruning choices made by an analyst could be inferior [5].
Applications of Layer-Aware Models
Layer-aware models have found applications in various domains where classification tasks are critical. Some notable applications include:
Medical Diagnosis
Imaging procedures are central to present day medicine and are especially important in producing diagnostic data concerning a multitude of disorders. These images can now be analyzed, through machine learning models greatly enhancing the medical field, diseases can be detected at such early stages. However, a vast number of modern models are complex and are not fit for real-time applications as well as other environments with limited computational capabilities.
To overcome this challenge, the layer-aware models capture and maintain only the vital layers when endeavoring to diagnose a certain disease. These models cut those they deem less important or ineffective, thus overcoming the outdated way of handling layers that slows down the process without compromising the result. Therefore, they facilitate the development of faster and enhanced medical diagnosis tools that can run with edge devices such as the mobile phone and portable medical devices.
For instance, in the implementation of segmentation of Retinal diseases using Optical Coherence Tomography (OCT) images, layer-aware models can improve diagnostic precision with low computational complexity. This efficiency is especially valuable in reactive health care centers and mobile clinics where high performance is of paramount importance.
Also, such layer-aware models can enhance the portability of diagnostic tools across the layers of imaging techniques. Using the patterns they are trained from images, the algorithms can be developed to predict with good success from X-rays, MRI and CT scans making them adaptable solutions for the healthcare sector. If these models are optimized in a way, healthcare providers can use these AI-based diagnostic tool in areas with less computational power thereby increasing the reach of healthcare.
Natural Language Processing (NLP)
NLP has seen great strides in recent years due to approaches such as transformer models, that includes BERT, GPT, and LLaMA. By learning the major objectives of these models, it is generalized that they are brilliant in language related tasks such as sentiment analysis, machine translation and question answering. But due to their extensive size and high complexity they are not suitable for deployment on edge devices and real time applications.
These features can be beneficial for applying layer-aware pruning techniques that provide deletions of those layers which are less influential, but do not significantly affect the transformer models’ understanding of the language. These optimizations bring down the model size, and inference time, bringing to the probability that these models can be deployed on smartphones, IoT devices, and embedded systems, among others.
For example, layer-aware pruning can be used on top of BERT to produce task-specialized versions such as for the customer support chatbots or virtual assistants. Through several elimination of the unnecessary layers, organization can respond more quickly while maximizing the utilization of computational power with no spatial effect on the quality of language translation. Also, this technique can minimize the energy used by NLP models to operate thus leading to the use of green approaches in artificial intelligence.
Layer-aware models also help NLP systems to be rather flexible concerning the application to different languages and dialect [7]. They can work with the most significant layers solely for a specific language and this way deliver higher accuracy at language-specific tasks without excessive computational intensity. All these DCs are crucial for the pursuit of building inclusive AI systems that take into account different linguistic communities globally.
Autonomous Vehicles
AVs depend on the detection and identification of objects in real-time to operate safely on the roads. These systems incorporate the use of machine learning algorithms, and must analyze large amounts of data from cameras, LiDAR and other sensors in real-time. High accuracy is important for driving safety, while at the same time, minimizing total execution time is important for autonomous driving systems.
Indeed, their layer-aware structure can maximize the effectiveness of object detection and classification tasks with lower models of fewer layers. By eliminating unnecessary layers, these models can easily be deployed on edge computing devices installed within vehicles ranging from onboard computers to control units. This optimization enables self-driving cars to act promptly following detection of their environment and hence safe and efficient.
For example, a layer-aware model property used in the context of a pedestrian detection will be able to detect the features like shape, movement or proximity, excluding all the useless information [8]. This limited processing cuts down on the amount of computation complexity and slows up the system’s reaction to possible dangers while increasing the number of frames per second.
Furthermore, layer-aware models can precisely be tuned to the specific vehicle dynamics of driving in city, on freeways and off-road [9]. This indicates that autonomous vehicle systems can improve the functionality of a particular model through structural adaptation related to different situations on the road. The requirement of this adaptability cannot be over-stressed to create reliable self-driving cars that could function well in various terrains.
Future Directions
The topic of neural pruning as well as models with awareness of the number of layers is still young. Future research is likely to focus on the following areas:
- The expansion of automated tools that can perform layer-aware pruning with minimum human involvement.
- Extending layer-aware pruning with other optimization strategies like quantization and knowledge distillation to gain performance improvement.
- Developing models that can learn pruning algorithms that depend on the current input data and the current levels of computational resources available.
Conclusion
Models aware of layers can be considered as a large step forward in the development of neural networks. Through integrating knowledge of layers characteristics during pruning these models can improve the classification accuracy as well as diminished computational expenses. That is why further integration of AI in various fields will require the use of effective and precise neural networks. This is where neural pruning, especially for use in layer-aware models, creates a fertile pathway towards the creation of such incredible possibility. Despite the existing structural and functional problems, continuous improvement in research and development can mitigate these problems and contribute to better and efficient powerful systems of AI.
References
- Song, Z., Xu, Y., He, Z., Jiang, L., Jing, N., & Liang, X. (2022). Cp-vit: Cascade vision transformer pruning via progressive sparsity prediction. arXiv preprint arXiv:2203.04570.
- Zhao, K., Jain, A., & Zhao, M. (2023, April). Automatic attention pruning: Improving and automating model pruning using attentions. In International Conference on Artificial Intelligence and Statistics (pp. 10470-10486). PMLR.
- Chen, D., Lin, K., & Deng, Q. (2025). UCC: A unified cascade compression framework for vision transformer models. Neurocomputing, 612, 128747.
- Song, Q., Cao, J., Li, Y., Gao, X., Shangguan, C., & Liang, L. (2023, November). On efficient federated learning for aerial remote sensing image classification: A filter pruning approach. In International Conference on Neural Information Processing (pp. 184-199). Singapore: Springer Nature Singapore.
- Song, Q., Cao, J., Li, Y., Gao, X., Shangguan, C., & Liang, L. (2023, November). On efficient federated learning for aerial remote sensing image classification: A filter pruning approach. In International Conference on Neural Information Processing (pp. 184-199). Singapore: Springer Nature Singapore.
- Vijay Badrinarayanan, Alex Kendall, and Roberto Cipolla. Segnet: A deep convolutional encoder-decoder architecture or image segmentation. IEEE transactions on pattern anal-ysis and machine intelligence, 39(12):2481–2495, 2017.
- Tianlong Chen, Yu Cheng, Zhe Gan, Lu Yuan, Lei Zhang, and Zhangyang Wang. Chasing sparsity in vision trans-formers: An end-to-end exploration. arXiv preprint arXiv:2106.04533, 2021.
- Cheng Chi, Fangyun Wei, and Han Hu. Relationnet++: Bridging visual representations for object detection via trans-former decoder. arXiv preprint arXiv:2010.15831, 2020.
- Zhigang Dai, Bolun Cai, Yugeng Lin, and Junying Chen. Up-detr: Unsupervised pre-training for object detection with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1601–1610, 2021.



