
Algorithms are trained in the field of machine learning to automatically improve their performance on a given task by learning from data. Computer vision, natural language processing, and robotics have all seen breakthroughs thanks to advances in machine learning in recent years. The significance of machine learning is only going to rise in the coming years in tandem with the rising complexity of data and the growing demand for automation. In this article, we will discuss a few of the most significant machine learning algorithms you should be familiar with by 2023.
Linear Regression
Linear Regression
Logistic Regression
Logistic regression is a variant of linear regression that is used for binary classification problems. Based on one or more predictor variables, it is used to model the probability of a binary response variable. Marketing, finance, and medical diagnosis all make extensive use of logistic regression.

Decision Trees
Decision Trees
Machine learning algorithms known as decision trees are utilized for both classification and regression problems. Based on the values of the features, they divide the data in a recursive manner into smaller subsets. The objective is to develop a tree-like model that can be used to predict features’ values.
Random Forest
An extension of decision trees, a random forest makes use of an ensemble of trees to make predictions. A subset of the features for each tree is chosen at random, and the predictions from all of the trees are combined to make a final prediction. Random forests are utilized extensively in fields like natural language processing and computer vision due to their high accuracy and stability.
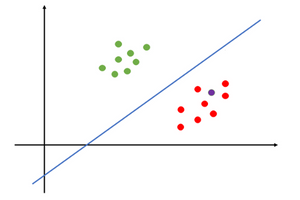
Support Vector Machines (SVM)
Support Vector Machines (SVM)
Support Vector Machines (SVM) are a type of machine learning algorithm used to solve classification and regression issues. They function by locating the ideal hyperplane or boundary that divides the data into distinct classes. SVM is widely used in bioinformatics and text classification, and it is particularly useful for solving complex non-linear problems.
K-Nearest Neighbors (KNN)
K-Nearest Neighbors (KNN) is a straightforward and efficient machine learning algorithm for regression and classification problems. It works by making a prediction based on the labels or values of the k closest neighbors to a given test example. In fields like image classification and recommendation systems, KNN is frequently used.
Naive Bayes
Classification problems are handled by the probabilistic machine learning algorithm known as Naive Bayes. It works by modeling the probability of a class based on the values of its features using Bayes’ theorem. In fields like spam filtering and text classification, Naive Bayes is widely used.

Neural Networks
Neural Networks
Machine Learning Algorithms Inspired by the Human Brain Neural networks are a type of machine learning algorithm. They are widely used for image classification, natural language processing, and speech recognition, among other things. Each layer of interconnected nodes in a neural network carries out a straightforward computation.
Convolutional Neural Networks (CNN)
Convolutional neural networks are a kind of neural network that are made to solve problems with image classification. Predictions are made using a fully connected layer after the image is convolved using multiple filters to extract features. CNNs have achieved state-of-the-art results on many images.



