
Perhaps you already know that data scientists identify patterns in massive volumes of data. But do you know how? They use many different machine learning algorithms to translate the data into actionable insights based on which organizations make strategic business decisions. They need to choose the right algorithm to solve the problem at hand. Random Forest is one such powerful machine learning algorithm. If you’re wondering what Random Forest is all about, why you should use it, how you can use it, etc, just continue reading and everything will become clear.

What is the Random Forest?
What is Random Forest?
Random Forest is a versatile and powerful supervised machine learning algorithm. Basically, you can think of it as an ensemble model of decision trees. Random Forest can be used for both regression and classification problems in Python and R.
Before delving deeper into Random Forest, you need to understand the associated concepts first. So, here’s a snapshot of the related concepts.
Supervised machine learning
Machine learning is divided into three key categories namely supervised learning, unsupervised learning, and reinforced learning. In supervised machine learning, a training dataset is used to create the algorithm. Many different examples of inputs and outputs are used to train the algorithm so that it can learn how to classify fresh input data and predict future outcomes.
Regression and classification
Both regression and classification are parts of supervised machine learning. We use regression algorithms to predict the output, which is a continuous or real value such as age, salary, price, etc. Classification algorithms are used to classify or predict the categorical output. For instance, an email spam filter is able to categorize every email into either of two classes – spam or not spam.
Decision trees
A decision tree is the most effective machine learning modeling technique widely used for classification and regression problems. When it comes to finding solutions, decision trees make hierarchical, sequential about the outcomes variable depending on the predictor data. There are three building blocks of a decision tree – a root node, branches, and leaves. To make it simple to understand, you can think of a decision tree as a flowchart, which draws an understandable pathway to an outcome or decision. It starts at one point and branches off into multiple directions. Each branch of a decision tree provides different outcomes possible. Basically, it’s a set of rules that we use to predict future data.
Basically, a Random Forest is only a bunch of decision trees grouped together. However, it’s important to understand that in a Random Forest all the trees are randomly mixed together. Therefore, when you use a single decision tree, it’ll come up with a set of rules based on the inputted training dataset. But when the same training dataset is inputted in a Random Forest algorithm, it’ll select features and observations randomly to build multiple decision trees and average the results of each of them.
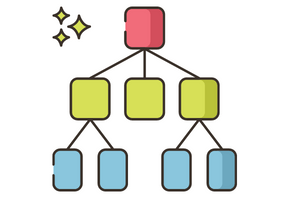
How to create a Random Forest using decision trees?
How to create a Random Forest using decision trees?
To do this, you need to understand how to build a decision tree first. Since the key objective of a decision tree is to make the most favorable choice at each node’s end, it’s important to avoid impurity and reach maximum purity. To develop a better understanding of how a decision tree is built, you need to learn about its building blocks.
Let’s try to understand the following fundamental concepts.
Entropy
We use entropy to measure the disorder, information, or purity of a dataset. If a dataset has mixed classes, it has more disorder and its entropy value will be higher. Therefore the potential for extracting information from it is also higher. On the contrary, a dataset with only one class doesn’t have much potential for information extraction.
Information Gain
We calculate the difference in entropy before and after we split the dataset to assess how ideal a feature is for splitting. Information gain refers to the amount by which a dataset’s entropy reduces due to the split. We use information gain when training decision trees as it helps to reduce uncertainty in them. A high information gain refers to the removal of a significant degree of uncertainty.
Gini Index
The Gini index is another measure for purity, which’s used by the Classification and Regression Tree (CART) algorithm. It is based on Gini impurity that measures how frequently a randomly selected element is incorrectly labeled in case it was labeled randomly according to distribution. If a dataset has two classes, the Gini index’s range remains between 0 and 0.5. In case the dataset is pure, it is 0, and if two classes are equally distributed it is 0.5. Therefore, we should try to have it reach 0 because that’s where it’ll be maximally pure and minimally impure.
Now that you’ve got an overview of the key mathematical concepts that are used in training decision trees, it’s time to take a look at Random Forest.
As we’ve already touched upon, the major difference between the Random Forest algorithm and the decision tree algorithm is that in the former, segregating nodes and establishing root nodes are randomly done.
Bagging
In Random Forests, the usual technique of bagging is applied by the training algorithm to tree learners. In the bagging technique, different samples of training data are used instead of only one sample. Here, decision trees are trained on a subset of the actual training dataset.
Bootstrapping of the training dataset
The subsets are obtained through random feature sampling and row sampling from the dataset – a method called bootstrapping. The sample datasets are reduced into summary statistics depending on the observation and combined by aggregation. We can Bootstrap Aggregation to reduce high variance algorithms’ variance.
Variance
Variance refers to an error that occurs from sensitivity to slight fluctuations in the training dataset. A high variance will lead to model noise or irrelevant data in the dataset rather than signal or the intended outputs – a problem called overfitting. Note that in training, an overfitted model can perform well but in an actual test, it won’t be able to differentiate the signal from the noise.
The majority rule
For the same input vector, slightly different predictions will be made by slightly differently trained trees. Generally, we apply the majority rule to decide on the final output. It means the prediction made by the majority of the trees is considered as the final output.

The key advantages and disadvantages of Random Forest
The key advantages and disadvantages of Random Forest
Random Forests offer a multitude of advantages – from relative ease of use to efficiency and accuracy. In addition, if you’re a data scientist and planning to utilize it in Python, you can use an efficient and simply random forest classifier library in scikit-learn. Let’s take a look at the pros and cons of Random Forests.
Advantages
- A Random Forest is significantly more efficient compared to a single decision tree when you’re performing analysis on a bigger database.
- Random Forests have the default ability to correct for the habit of overfitting of decision trees to their training datasets. You already know that overfitting results in inaccurate outcomes. You can almost entirely resolve the issue of overfitting when executing random forest algorithms with the help of random feature selection and bagging method.
- A neural network, which mimics the way of thinking of a human brain to disclose the underlying relationship present in a dataset, is more efficient than a Random Forest. However, a neural network is much more complicated than a Random Forest. Since it requires less expertise and time to build a Random Forest, the method often proves to be more useful for less experienced data science professionals.
Disadvantages
- Like any other tool, Random Forests also come with a few downsides. Since a Random Forest comprises several decision trees, it may require lots of memory, especially for larger projects. It may make it slower compared to some other algorithms.
- Decision trees are the building blocks of a Random Forest and decision trees frequently experience the issue of overfitting, which may affect the entire forest. However, generally, Random Forests prevent this problem by default. This is because they utilize features’ random subsets and use them to build smaller trees. The processing speed might get reduced due to it but accuracy will increase.
When you shouldn’t use Random Forests
There are some situations where Random Forest algorithms may not be the ideal option. These include the following.
- If you’re working with very sparse data, Random Forests may not generate good results. Here, an invariant space will be produced by the bootstrapped sample and the features’ subset, which may result in unproductive splits affecting the outcome.
- When it comes to performing extrapolation, random forest regression isn’t the best choice. This is the reason the majority of random forest applications are related to classification.
Parting thoughts
Once you’ve developed a good understanding of these fundamentals, you should join a machine learning course to master these concepts. These courses from a reputable institute will help you learn a wide range of other skills along with the Random Forest algorithm, even if you’re completely new to machine learning.



