
Algorithms and statistical models are used in the field of machine learning to help computers learn from data. The distinction between supervised and unsupervised learning is essential in machine learning. In this article, we will look at the differences between these two approaches and when to use each one.
Supervised Learning
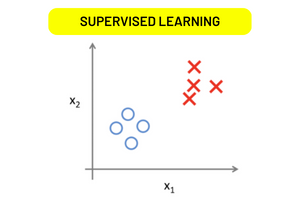
Supervised Learning
Learning from Labeled Data is an aspect of supervised learning. The machine learning model learns to predict the output based on the input after the correct output is labeled on the input data. A spam email filter, for instance, is first trained on a group of emails where both text and the label of the emails are provided. After the training, the filter takes the text of an email as its input and determines whether or not it is spam.
The steps of supervised learning are as follows:
Collection of data: Gather data with labels that include both the input and the output.
Preprocessing of data: Preprocess the data and clean it up.
Choosing a model: Select a suitable machine learning model for the issue.
Model training: Use the labeled data to teach the machine learning model.
Evaluation of a model: Analyze the machine learning model’s performance on a test set.
Model deployment: Apply the model to new data to make predictions.
Linear regression, logistic regression, decision trees, random forests, and neural networks are all common supervised learning algorithms.
Unsupervised Learning
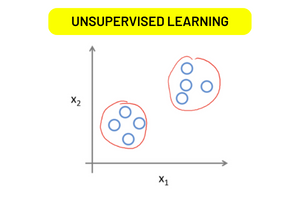
Unsupervised Learning
With unsupervised learning, the data come without any labels. The machine learning model learns to recognize patterns and structure in the data without the input data being labeled with the correct output. In customer segmentation, for instance, the model learns to group customers according to their behavior using the input data. When training this model, the dataset does not include the segments of each customer.
The steps that make up unsupervised learning are as follows:
Collection of data: Gather unlabeled data consisting solely of the input.
Preprocessing of data: Preprocess the data and clean it up.
Choosing a model: Select a problem-appropriate unsupervised learning model.
Model training: Use the unlabeled data to teach the unsupervised learning model.
Evaluation of a model: Make use of your domain expertise to evaluate the effectiveness of the unsupervised learning model.
Model deployment: Utilize the model to discover structure and patterns in brand-new data.
Clustering, principal component analysis (PCA), and association rule mining are a few common unsupervised learning algorithms.
Supervised vs. Unsupervised Learning
When to Use Supervised vs. Unsupervised Learning
When the problem has labeled data and clear input and output, supervised learning is used.
Image recognition, natural language processing, and stock price prediction all make use of classification and regression.
When unlabeled data are available and the problem lacks clear input and output, unsupervised learning is utilized.
Customer segmentation, anomaly detection, and exploratory data analysis all make use of them frequently. Practitioners of machine learning can select the appropriate approach for their particular problem and maximize the performance of their models by comprehending the distinctions between these two approaches.



