
Over the last decade, Artificial Intelligence (AI) has been significantly reshaped, and now multi-agent AI systems take the lead as the most powerful approach to solving complex problems. They are based on a system that features multiple autonomous agents cooperating in enhancing reasoning, retrieval, and response generation [1]. With Hugging Face Code Agents, one of the perhaps coolest things we can do in this domain today is build modular, open-source AI applications. Combined with Qwen2. The Mistral team believes if we get the right prompt and the right techniques applied to the right integration state-of-the-art language model capabilities such as 5–7B are very much capable of offering RAG-like features in different aspects such as demand forecasting, knowledge extraction, and conversational AI[2].
Here is a comprehensive step-by-step tutorial for building an open-source, local RAG system using Hugging Face Code Agents and Qwen2. 5–7B. In order to do that, we need to understand the base rationale behind multi-agent AI systems, how RAG helps to increase response accuracy, and a step-by-step hands-on tutorial on creating these local, AI-enabled information retrieval and generation systems. Your end product will be a working POC that runs locally and still gives you data privacy and efficiency.
Understanding Multi-Agent AI Systems
The multi-agent AI system is a system in which multiple intelligent agents work together in a way that helps them all accomplish common tasks more efficiently. Unlike traditional AI models that work in isolation, multi-agent systems (MAS) leverage decentralized intelligence that separates specific tasks per agent. This makes it easier to scale, optimize the use of resources, and generalize, thus making MAS preferred in applications including but not limited to autonomous systems, robotics, financial modeling, and conversational AI [3].
Key Components of a Multi-Agent System
- Retrieval Agent – Retrieve relevant data from its local knowledge base or external sources like the internet. This allows the system to leverage current, situationally appropriate data [4].
- Processing Agent – Like a traditional researcher, organizes and distills the information to make it useful for the next steps. It allows for faster filtering against noise, extraction of key insights, and organization of information [5].
- Generation Agent – Large Language Model (LLM) (e.g., Qwen2. 5–7B) to produce responses from the structured information. This agent ensures that the output is semantically coherent [6].
- Evaluation Agent – Evaluating generated responses for properties discusses generation quality, such as accuracy or triviality, and consistency with the system’s established standard, before being shown to the user [7].
Multi-agent AI systems enable multi-step, on-demand, reasoning by tapping into the specialized knowledge of individual agents, creating more adaptive, efficient, and context-aware AI applications. Use cases such as real-time decision-making, AI-powered virtual assistants, and intelligent automation in healthcare, finance, and cybersecurity [8] would benefit from this architecture, and, it offers predictability and performance.
Why Hugging Face Code Agents?
In the past few years, AI has undergone a tremendous transformation, and multi-agent AI systems have become a powerful approach to solving complex problems. Multi-agent systems (MAS) consist of multiple independent agents operating in tandem to further progress reasoning, retrieval, and response generation, unlike traditional AI models that unilaterally take actions. This results in clearer, more scalable, adaptive, and efficient AI solutions ideally fit for domains like automated decision-making, virtual intelligence assistants, and autonomous robotics [9].
One of the most exciting news in the space is possibly Hugging Face Code Agents – highly modular, open-source, AI applications can be built using them. By leveraging Qwen2. Large language models that have recently been used (e.g. 5–7B) can solve this problem well because these systems can get good retrieval-augmented generation (RAG). Overall, RAG leverages the strengths of both retrieval-based and generative AI models which help improve response accuracy, deliver context-aware answers, and enhance knowledge extraction. In demand forecasting, knowledge-based systems, and conversational AI, this is helpful [10].
This article focuses on building an open-source, local RAG system using Hugging Face Code Agents and Qwen2. 5–7B. We will learn the basic concept of multi-agent AI systems, how to use RAG to enhance responses in AI systems, and the practical implementation of solving local use cases driven by AI for information retrieval and generation. At the end, you will have a working prototype on the local machine which guarantees data privacy, and speed and improves AI decision [11].
Setting Up the Environment
To realize our multi-agent RAG system, we first prepare the environment and install related dependencies.
Step 1: Install Required Libraries
This installs:
- Transformers: Hugging Faces library for reading WPS, pre-trained models on NLP tasks (text generation, translation, QA.) We use it for performing inference on the Qwen2. We also trained a 5–7B model, which produces AI responses based on retrieved context.
- Datasets: A Hugging Face library that makes it easier to work with massive datasets without a struggle — load the data, preprocess the data, and manage your knowledge base. Since it plays an essential role in modifying and managing big text data used in retrieval-augmented generation (RAG) systems.
- Hugging Face Hub: A repository of pre-trained models, datasets, and other AI resources. Using some tools that we use to download and integrate models such as Qwen2. And the key dataset for improving retrieval-centric AI flows from 5–7B.
- LangChain: A complete framework to connect different Ingredients to build complex AI apps — whether retrieval, response generation, etc. It organizes our pipeline by wrapping FAISS for document retrieval, Sentence-Transformers for embeddings, and Transformers for model inference.
- Sentence-Transformers: A library dedicated to generating high-quality text embeddings. These embeddings are necessary to perform similarity searches since they serve as numerical fingerprints of pieces of text that we efficiently compare in our retrieval pipeline to rank them by relevance.
- FAISS: acebook AI Similarity Search, a library for efficient similarity search and clustering of dense vectors. It helps in the efficient retrieval of documents by indexing the embeddings, making it suitable for semantic search through large datasets. It is crucial for retrieving relevant knowledge to pass to the AI model that generates the response.
Step 2: Load Qwen2.5–7B
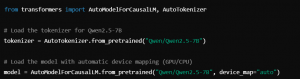
- Imports necessary classes: The import AllModelForCausalLM and AutoTokenizer from the transformers library.
AutoModelForCausalLM is a generic class that loads any causal language model and you can easily switch between those different models without changing the code.
AutoTokenizer, which tokenizes text; takes input text and splits it into smaller pieces, or tokens, that the model can process more efficiently.
- Loads the tokenizer: The tokenizer is responsible for transforming raw text input into numerical token IDs that the model can work with.
This stage ensures proper text formatting and alignment with the model during the pre-training phase, thereby increasing accuracy and efficiency.
- Loads the model: : The Qwen2. 1: The 5-7B model is loaded using device_map=”auto”, as this loads the model on the best available hardware.
Also, if your machine has a GPU, then the model will load on there for quicker inference.
Otherwise, it falls back to the CPU, so it works everywhere.
These performance optimizations can utilize the available capabilities of the user’s system.
Building the Local RAG System
It is a hybrid framework that first retrieves pertinent knowledge information from external sources, then answers using the information retrieved in the previous steps. Instead of just depending on the information learned during the main training process, RAG leverages the dynamically obtained and integrated knowledge from an infinitely large reference corpus, which makes it suitable for application scenarios such as question-answering, chatbots, knowledge extraction, and document summarization [12].
Key Components of Our RAG System
- Retrieval Agent – This agent retrieves relevant documents from an external knowledge base. It uses Facebook AI Similarity Search (FAISS) — an efficient optimized vector search library built for large-scale similarity-based retrieval. It allows for fast nearest-neighbor searching, enabling the system to rapidly identify the most relevant information from structured or unstructured databases [13]
- Processing Agent – Once documents have been fetched, the information they contain is often redundant or unstructured. The processing agent is responsible for taking this data and parsing it to retain relevant parts, summarizing it to include only the relevant sections, and finally preparing the data to be coherent and ready to display before sending them to the language model. This process is essential for preserving response clarity, factual consistency, and contextual relevance [14].
- Generation Agent – The processing agent uses Qwen2 to synthesize responses. 5–7B, an advanced generation/large language model (LLM). Through its fusion of retrieved and structured information, the model yields more accurate, informative, and contextually relevant responses than traditional generative approaches. [15]; this benefits domain-specific AI applications, research-driven conversational agents, and AI-powered decision support systems.
The RAG system makes AI power more fact-based, reliable, and context-aware by combining dynamic knowledge retrieval with state-of-the-art text generation by integrating these three agents. This vastly increases AI models’ performance on complex queries while improving accuracy.
Step 1: Creating a Local Knowledge Base

FAISS — About this code
Loading an embedding model The first step in the script is to load an embedding model, it loads a sentence embedding model which is pre-trained (all-MiniLM-L6-v2) using HuggingFaceEmbeddings This model transforms text into high-dimensional numerical vectors that carry semantic meaning. They allow for similarity-based searches, as the generated embeddings capture the structure and context relationships of the documents.
Creating a FAISS index: The script reads through sample text documents, transforms them into embeddings, and adds them to an FAISS index. FAISS is an algorithm for efficient nearest neighbor performed by the company Facebook AI similar to searches fast, so relevant documents can be retrieved efficiently. This acts as a local knowledge base, allowing for quick local lookups that do not depend on external databases. The indexed documents are then searchable and can be used to discover the most fitting information given a query.
Step 2: Implementing the Retrieval Agent
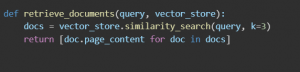
This function queries the FAISS index to retrieve the top 3 documents that match the most to the input query.
- similarity_search(query, k=3) returns the three most relevant documents.
- The results come back as a list of snippets.
Step 3: Implementing the Generation Agent
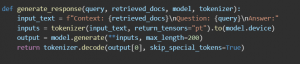
Here, it generates an AI-based response using the retrieved documents as context.
- A structured prompt is composed of the query and 0the retrieved documents, such that the model can use relevant background information to produce a coherent and informed response [16].
- Take an example of a text, known as input text: which means tokenizing words, adding special model tokens if necessary, and generating attention masks for effective processing [17].
- The model is then used for causal language modeling to predict the most likely response. The model generates text iteratively by taking into account previous tokens while generating an answer according to the context presented [18].
This function combines retrieved knowledge with natural language generation and improves the accuracy and relevance of responses, making it especially important for question-answering systems, chatbots, and knowledge-based AI applications [19].
References
- Jennings, N. R., & Sycara, K. (1998). “A Roadmap of Agent Research and Development.” Autonomous Agents and Multi-Agent Systems, 1(1), 7-38.
- Lewis, M., et al. (2020). “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.” Advances in Neural Information Processing Systems (NeurIPS).
- Wooldridge, M. (2020). Multi-Agent Systems: An Introduction to Distributed Artificial Intelligence. MIT Press.
- Russell, S., & Norvig, P. (2021). Artificial Intelligence: A Modern Approach (4th ed.). Pearson.
- Jennings, N. R., & Sycara, K. (1998). “A Roadmap of Agent Research and Development.” Autonomous Agents and Multi-Agent Systems, 1(1), 7-38.



